First things first: background and setup before dplyr
Michael D. Garber, PhD MPH
2022-08-23
This module motivates the use of R and describes some preliminary concepts and steps before we begin with the sessions on data wrangling and visualization.
1 What is R?
According to the R website, R is “a free software environment for statistical computing and graphics.” Its hashtag on Twitter is #RStats, but, as some have alluded to, R can do much more than statistics. For example, it can make maps, create websites, and, importantly, manipulate data.
Aside: I don’t view the manipulation and analysis of data (creating variables, counting things, putting things in groups, etc.) as necessarily within the realm of statistics, unless I intend to infer the results of that analysis to a larger or separate population.
Definitions of statistics aside, the point is that R is a programming language that allows you to perform most any data-manipulation, data-analysis, or data-visualization task (including statistics)!
2 Why R?
Why is R a good tool for manipulating and analyzing data?
2.1 R vs point-and-click data-analysis tools like Excel and ArcGIS
This post by Jesse Adler (a digital historian) is a well-written overview of the advantages of using a programming language like R to manipulate and analyze data rather than spreadsheet tools like Excel. Summarizing their post with another on the topic, here are my top four advantages of programming:
Every step is written down, so it’s easier to find and fix errors.
Easier to repeat analysis steps: suppose you realize you want to make a change upstream in your analysis that affects everything downstream of it. In R, this is straightforward: simply make the change, and rerun all of the code that relies upon it (and possibly make some changes to the downstream code to accommodate that change as needed). In a point-and-click interface like Excel or ArcGIS, you may have to repeat several point-and-click steps, which would take longer and be more susceptible to error.
There is a clear division between data entry and data manipulation and analysis: it’s easier to avoid the temptation of editing the raw data. Although you can certainly make a copy of raw data in Excel (e.g., copy to new sheet), it can be tempting to edit the raw data.
Easier to automate similar tasks. Frequently in data analysis, we repeat very similar steps, maybe just by changing one element. The ability to automate similar steps becomes especially important for bootstrapping where we effectively repeat the analysis hundreds of times while allowing some of the steps to randomly vary. This iteration of similar steps would be much more challenging in Excel.
To be clear, I think Excel is great, too. I use it often for simple analyses or for data entry. But I don’t use it as much as I once did for more involved analyses.
2.2 Why R vs SAS, STATA, and Python?
Okay, but there are other programming tools for data analysis (e.g., SAS, STATA, Python). Why R, specifically?
- It’s free. SAS and STATA cost money.
- It has an active, helpful, and friendly user community. Googling a topic along with “R” often leads to useful public discussion on forums like stackoverflow or RStudio community.
- It can manipulate spatial data and make maps. No need to switch software for GIS. In a data-manipulation workflow involving spatial data, the ability to switch seamlessly between aspatial and spatial data is very important.
- R can do a lot of cool stuff beyond the usual data wrangling and analysis. For example, with RMarkdown, you can generate html files to make websites (like this one), create interactive dashboards, and do lots more (see this amazing talk by R Markdown’s creator).
I know many people use and like Python, which is also free and shares many of R’s advantages. I don’t have much Python experience, so I can’t really comment on it. Every now and then, I encounter a situation where I wish I had Python skills (e.g., to use this package to compute measures on street networks from OpenStreetMap), but those situations are rare.
3 Install R and RStudio and become familiar with the user interface.
Let’s get up and running with R now.
- Install R and RStudio. R can be used as a stand-alone program, but RStudio, an integrated development environment (IDE), adds several helpful features that make coding in R easier.
- To download R, go to CRAN and download R from the location nearest you: https://cran.r-project.org/mirrors.html.
- Then, install RStudio Desktop (the free version) at this link: https://rstudio.com/products/rstudio/download .
The Appendix of this free online book, Hands-On Programming with R, by Garrett Grolemund, describes the installation process in more detail.
- Familiarize yourself with the RStudio interface. There are a few ways to write code in R, including:
Using a script. I almost always write code using a script, which is essentially a special text file that can be saved and edited as you would a Word document.
Using RMarkdown is another option. I made this web page using RMarkdown. It allows the author to include narrative text, code, and the code’s results in one streamlined document. RMarkdown is well-suited for something that will be presented (to someone besides yourself) and in my opinion is not the best choice for a typical data-analysis workflow, where I prefer scripts for their simplicity.
Using the console. Finally, if you just want to do a very basic task or calculation without creating a new file, you can type code in the console. I almost never use the console.
The book by Grolemund also provides an overview of RStudio’s user interface.
Here’s a screenshot of what the script window might look like:

3.1 Writing code vs writing a comment
On a particular line of code, anything followed by a # is considered by R to be a comment and will not be evaluated as code. Comments are a way to annotate your code to communicate with your future self or other collaborators. Text considered by R to be comments will change to a different color. Using RStudio’s default display settings, a comment in an R script will turn green.
#This is a comment.
#The below line is code:
x=1:2
x #this prints the object## [1] 1 24 Functions and packages
4.1 Terminology
Two often-quoted slogans describing R are that:
“Everything that exists is an object.”
“Everything that happens is a function.”
Fundamentally, when using R, you are using functions to perform actions on objects. As we’ll see explicitly when going over purrr, functions are themselves objects and can be manipulated by other functions.
R comes pre-loaded with a set of functions that can be used to analyze data. This is called “base R” and is the foundation upon which everything else in R is built.
Many commonly used functions, however, are not a part of base R but are instead part of a package. Packages are collections of functions with related goals. They can also include data and documentation as part of the bundle. For example, dplyr is a package of functions with a common philosophy for manipulating data, and it includes some demo datasets.
4.2 Install a package
Using a package requires first installing it with the install.packages("package_name") function. Installing a package means downloading it from CRAN (R’s central software repository) and storing it on your computer (R will decide where it goes) so that it can be used later. You can also install packages (or package versions) that aren’t on CRAN using devtools.
In RStudio, you can also install CRAN packages using the Tools dropdown,

which will prompt the following screen, where you can search for and install packages. In the background, this tool will run the install.packages("package_name") code.
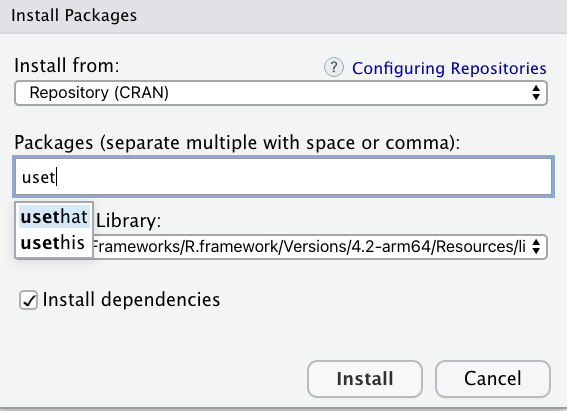
For this exercise, let’s install the full tidyverse. The tidyverse is a unique package in that it is a collection of packages, one of which is dplyr.
So here is our first code chunk to run:
install.packages("tidyverse")To run the code, put your cursor on that line or highlight that line of code, and then click the Run button above and to the right of the scripts window pane.
On Windows, the keyboard shortcut for Run is control+enter. On a Mac, it’s command+return.
In my experience, it’s best to let R pick where it installs the packages on your computer. This may depend on whether you’re using your own computer or, say, a work computer with limited access to some drives. If needed, you can specify where you want the package to land by adding the lib= "file path" argument in the install.packages() function. For example: install.packages("tidyverse", lib = "file-path").
4.3 Load the package
Now that the package is installed, load it (technically, attach it) using the library(package_name) function (no quotes around package name). Attaching the package tells R to make the functions from the package available for your current work session.
For additional details on package management, please see this module: https://michaeldgarber.github.io/teach-r/manage-packages.html
library(tidyverse)5 Here, here: a word on working directories and projects
5.1 Here package and projects
The folder in which R reads and writes files is called the working directory. For years, I used to set the working directory by typing the entire file path. This is not ideal practice for a few of reasons:
- It takes a long time to type a long file path.
- Typing file paths is prone to error. (How do I type the back-slash, \ or /? Do I need the : on a Windows path?)
- It’s hard-coded: If you were to change computers or share your code with someone, those working directories won’t work.
Fortunately, there’s a simple solution to these issues: Use the here package. This package creates a working directory relative to the folder containing the R project file (described below). This means that wherever your project is in the folder structure of your computer, the here() function to define your working directory and thus any read/write commands that rely on it will just work.
This code returns the current working directory.
library(here)## here() starts at /Users/michaeldgarber/Dropbox/Work/teach/teach-rhere()## [1] "/Users/michaeldgarber/Dropbox/Work/teach/teach-r"(Jenny Bryan’s ode to the here package is a great read.)
What is a Project? A Project is an RStudio file (.rproj) associated with a working directory that facilitates organization of files (code, data, other documents) and particular settings relevant for one, well, project. For example, to create this course, I created a project called teach-r. You can create a new project by either navigating to the top right of the RStudio interface, as in,

or by using the “File” dropdown, as in,
Note that in the screenshot below, all of folders and files in the folder containing the .Rproj file will conveniently appear in the “Files” tab (bottom right pane of a default RStudio session).

This folder structure mirrors the folder structure of your computer; it’s simply a way to access and manage files from directly within the RStudio interface. Here’s my corresponding Finder window (Mac):

It’s worth giving some thought to the project’s folder structure. There are no hard-and-fast rules, but I have taken this advice and, minimally, create separate folders for code (folder called scripts), input data that should never be modified (data-input), and processed data that is a result of code (data-processed). To make best use of the here package, these folders for scripts and data must be beneath the folder containing the .Rproj file.
You don’t have to use projects to use R or RStudio, but I’ve been convinced that it’s a good idea, in part because of how well projects pair with the here package.
5.2 Example: change working directory using here()
install.packages("here")library(here) #load package.Note when you load the here package, it will by default tell you where your working directory is. We can also confirm this using the getwd base-R function.
getwd() #base R## [1] "/Users/michaeldgarber/Dropbox/Work/teach/teach-r/docs"What if we want to change the working directory, to the “data-input” folder? Use the base-R setwd() function to set the working directory and the here::here() function to define the path relative to the project. Note the “data-input” folder is one level beneath the .Rproj file (screenshot above).
setwd(here("data-input"))
getwd() #check## [1] "/Users/michaeldgarber/Dropbox/Work/teach/teach-r/data-input"If we wanted to set the working directory to two folders beneath data-input, we would write: setwd(here("data-input","sub-folder","sub-sub-folder"). That is, we would write the name of each sub-folder in quotes after a comma. Note that here::here(), like base::file.path(), allows us to quote each folder in the path rather than use slashes. This makes the path easier to write and more robust for switching between operating systems than if we had to write, say "data-input/sub-folder/sub-sub-folder".
If we want to change it back to the original directory containing the project? Simply use here() without specifying an argument.
setwd(here())
getwd() #check## [1] "/Users/michaeldgarber/Dropbox/Work/teach/teach-r"5.3 Example: save a file to a working directory and a taste of dplyr
As mentioned, the tidyverse contains lots of packages. One of them is datasets, which includes, well, several datasets that can be used for demos like this one. I’m a Michigander, so let’s grab the dataset on the water levels of Lake Huron from 1875 - 1972, make a few changes to it, and save it to a local folder.

The below code chunk simply creates a copy of the LakeHuron dataset and calls it lake_huron_raw. In the next line of code, we print the object by typing its name: lake_huron_raw.
Side-note: the package_name::object syntax, as in datasets::LakeHuron, is R’s way of explicitly stating which package the object is coming from. Technically, it loads the package via namespace, elaborated upon in another module: https://michaeldgarber.github.io/teach-r/manage-packages.html. If the package has been attached via library(package_name), then we could write, lake_huron_raw = LakeHuron.
#Define new object called lake_huron_raw.
lake_huron_raw = datasets::LakeHuron
lake_huron_raw #Take a look at it.## Time Series:
## Start = 1875
## End = 1972
## Frequency = 1
## [1] 580.38 581.86 580.97 580.80 579.79 580.39 580.42 580.82 581.40 581.32
## [11] 581.44 581.68 581.17 580.53 580.01 579.91 579.14 579.16 579.55 579.67
## [21] 578.44 578.24 579.10 579.09 579.35 578.82 579.32 579.01 579.00 579.80
## [31] 579.83 579.72 579.89 580.01 579.37 578.69 578.19 578.67 579.55 578.92
## [41] 578.09 579.37 580.13 580.14 579.51 579.24 578.66 578.86 578.05 577.79
## [51] 576.75 576.75 577.82 578.64 580.58 579.48 577.38 576.90 576.94 576.24
## [61] 576.84 576.85 576.90 577.79 578.18 577.51 577.23 578.42 579.61 579.05
## [71] 579.26 579.22 579.38 579.10 577.95 578.12 579.75 580.85 580.41 579.96
## [81] 579.61 578.76 578.18 577.21 577.13 579.10 578.25 577.91 576.89 575.96
## [91] 576.80 577.68 578.38 578.52 579.74 579.31 579.89 579.96That’s hard to read. Let’s clean it up and save it.
Don’t sweat the dplyr code itself just yet (introduced next session), but, as an appetizer, we convert the dataset into an easier-to-work-with format (a tibble) using as_tibble(), rename its one variable from x to level_ft using rename(), and create a new variable called year using mutate(), defined based on the row number (row_number() returns the row number). And we connect all these steps together using the pipe operator (%>%).
lake_huron_transformed = lake_huron_raw %>% #use the object defined above
dplyr::as_tibble() %>%
dplyr::rename(level_ft =x) %>% #rename variable to "level_ft"
dplyr::mutate(year = row_number()-1+1875) #add a column for year
lake_huron_transformed #look at the transformed data## # A tibble: 98 × 2
## level_ft year
## <dbl> <dbl>
## 1 580. 1875
## 2 582. 1876
## 3 581. 1877
## 4 581. 1878
## 5 580. 1879
## 6 580. 1880
## 7 580. 1881
## 8 581. 1882
## 9 581. 1883
## 10 581. 1884
## # … with 88 more rows
## # ℹ Use `print(n = ...)` to see more rowsNow we have an easier-to-comprehend dataset called lake_huron with two columns. I’d like to save it to the folder called “data-processed,” which is one level beneath the project file. The save() function takes the object to be saved as its first argument and what it will be named on the computer as its second argument. A good (not the only) file format with which to save R objects locally is .Rdata.
library(here)
setwd(here("data-processed"))
getwd() #check to confirm## [1] "/Users/michaeldgarber/Dropbox/Work/teach/teach-r/data-processed"save(lake_huron_transformed, file = "lake_huron_transformed.RData")That concludes the background material. Now onto our first dplyr module (https://michaeldgarber.github.io/teach-r/1-dplyr-nyt-covid.html).
Copyright © 2022 Michael D. Garber