Monte Carlo simulations and boots with the purrr::map_dfr()
Michael D. Garber, PhD MPH
2022-08-23

{kind=link}
1 Learning objectives
Provide a working definition of Monte Carlo simulations and bootstrapping.
Perform each using R.
2 Motivation
2.1 Sources of uncertainty from multiple sources
Almost any epidemiological or statistical analysis has uncertainty. Uncertainty may arise within the dataset available for analysis (the sample) or, if we aim to infer characteristics of a larger population from the sample, from sampling. For example, suppose we want to estimate the prevalence of Covid-19 in a county. To do so, we randomly sample 1,000 people from that county and test them using at-home antigen tests. Home tests have good specificity but fairly poor sensitivity,1 meaning some of the negative results were probably truly positive (false negative). And because the poor sensitivity is a property of the test, not the sampling, this error is expected to occur regardless of the sample size. In addition to this systematic error in measurement, uncertainty arises from the sampling because we don’t know if the Covid prevalence among the 1,000 people we tested represents that of the county. By chance, we could have tested a particularly healthy or sick sample.
In our final estimate of prevalence, how would we go about summarizing its uncertainty, considering both the expected error in measurement and random error from sampling? Statistics of course has fundamental methods for estimating uncertainty from multiple sources, but many traditional methods for estimating variance involve complex math.2 To simplify the math, analysts often make assumptions that may not hold, for example that random variables considered in the analysis are independent from one another. In this particular example, the two sources of uncertainty (test accuracy and sampling) may be independent from one another, but that independence often does not hold.
2.2 When independence between sources of uncertainty does not hold
For example, in my dissertation, I aimed to estimate the total amount of bicycling on every road in Atlanta. I had two sources of information, both of which had uncertainty. The first was a sample of bicycling on every roadway obtained from a smartphone app, inducing sampling variability and probably selection bias.3 The second was a set of about 15 bicycle counters located throughout the city, assumed to accurately measure all bicycling in that location. I used these counters to estimate the proportion of bicyclists captured by the app. In this analysis, bike traffic in the smartphone-generated sample was correlated with the proportion captured in the app over the counter locations, meaning that estimating the variance of their product should consider this lack of independence. Accurately estimating the variance arising from both of these inter-related sources by appropriately considering their covariance using traditional pen-and-paper statistical methods, and propagating that combined uncertainty through other steps in the analysis which may themselves have uncertainty, would be difficult.
3 Estimating variability via repeated (re)sampling of random variations
Fortunately, we can estimate uncertainty using computer simulations which largely obviates the need to do complex math. Two broad ways to estimate uncertainty using computer-based simulation techniques are Monte Carlo simulations and bootstrapping. In addition to easing the math, these simulation methods can help the analyst see how and when something varies in the analysis, which facilitates clarity and understanding.
3.1 Monte Carlo simulations
“Monte Carlo simulation is a method of analysis based on artificially recreating a chance process (usually with a computer), running it many times, and directly observing the results.”4
An important aspect of a traditional Monte Carlo simulation is that the distribution (i.e., its mean and variance) of each individual source of uncertainty is specified by the analyst. It is not estimated from the data. Monte Carlo simulations are useful to propagate multiple sources of variation throughout an analysis pipeline to assess the impact of all sources of uncertainty on the final result. And, as noted, they’re especially helpful compared with traditional (non-computer-based) statistical methods when those sources of variation are correlated with one another.
3.2 Bootstrapping
Monte Carlo simulation in its typical implementation cannot, however, directly estimate the sampling distribution. But bootstrapping can.
“In statistics…, bootstrapping has come to mean to re-sample [with replacement] repeatedly and randomly from an original, initial sample using each bootstrapped sample to compute a statistic. The resulting empirical distribution of the statistic is then examined and interpreted as an approximation to the true sampling distribution.”5
The bootstrap was introduced by Bradley Efron in the late 1970s.6,7 There are many forms of bootstrapping, including ways to bootstrap residuals from regression models.8 In its most basic form, to bootstrap means to re-sample observations from the sample, compute summary statistics from each re-sampled sample, and use the distribution of those summary statistics to infer the sampling distribution.
The bootstrap is similar conceptually to Monte Carlo techniques because it involves randomly changing the data over repeated iterations and summarizing results of those iterations. The key difference is that the bootstrap estimates a distribution using data we have, and, under the Monte Carlo technique described, the distribution of each variable is specified by the analyst.
4 Example code for each method using purrr::map_dfr()
4.1 Monte Carlo simulation
Suppose we have a state with 100 counties. We simulate one single dataset, specifying that the mean county population is 1,000 and the probability of a binary demographic variable (dem; say urban versus rural) is 0.5. The prevalence (prev) depends in part on pop and dem, and the number of cases in the county is estimated from pop and prev.
library(tidyverse)
library(truncnorm)
set.seed(11)#set the seed so this dataset is always the same.
monte_carlo_sim_frozen = 1:100 %>%
as_tibble() %>%
rename(county_id = value) %>%
mutate(
state = 1,
pop = rpois(n=n(), lambda=10000), #poisson dist. mean = var=1000
dem = rbinom(n=n(), size=1, prob =.5), #binomial dist.
prev = rtruncnorm( #truncated normal so prevalence is bounded by 0,1
n=n(),
a=0,
b=1,
mean=0.05+(pop/50000)+(dem/10),
sd=0.05 +(pop/200000)+(dem/40)),
n_cases = as.integer(pop*prev),
)
monte_carlo_sim_frozen## # A tibble: 100 × 6
## county_id state pop dem prev n_cases
## <int> <dbl> <int> <int> <dbl> <int>
## 1 1 1 9940 1 0.492 4891
## 2 2 1 9780 1 0.455 4448
## 3 3 1 9863 1 0.492 4849
## 4 4 1 9884 0 0.238 2352
## 5 5 1 10132 0 0.243 2464
## 6 6 1 10062 1 0.435 4378
## 7 7 1 9995 0 0.177 1773
## 8 8 1 9995 1 0.634 6340
## 9 9 1 9965 0 0.223 2219
## 10 10 1 9995 0 0.211 2111
## # … with 90 more rows
## # ℹ Use `print(n = ...)` to see more rowsNote that population pop and prev are correlated. That is, they’re not independent from one another, so when estimating variability of their product, n_cases, that correlation should be considered.
cor(monte_carlo_sim_frozen$pop,
monte_carlo_sim_frozen$prev)## [1] -0.05167318What is the mean and standard deviation number of cases per county? Note we have not run any replications yet. This is just one iteration of the theoretical dataset of counties in a state.
monte_carlo_sim_frozen %>%
group_by(state) %>%
summarise(
n_cases_mean = mean(n_cases),
n_cases_sd = sd(n_cases)) %>%
ungroup()## # A tibble: 1 × 3
## state n_cases_mean n_cases_sd
## <dbl> <dbl> <dbl>
## 1 1 3053. 1250.What is the distribution of the number of cases between counties in the state for this one replication?
monte_carlo_sim_frozen %>%
ggplot(aes(n_cases))+
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.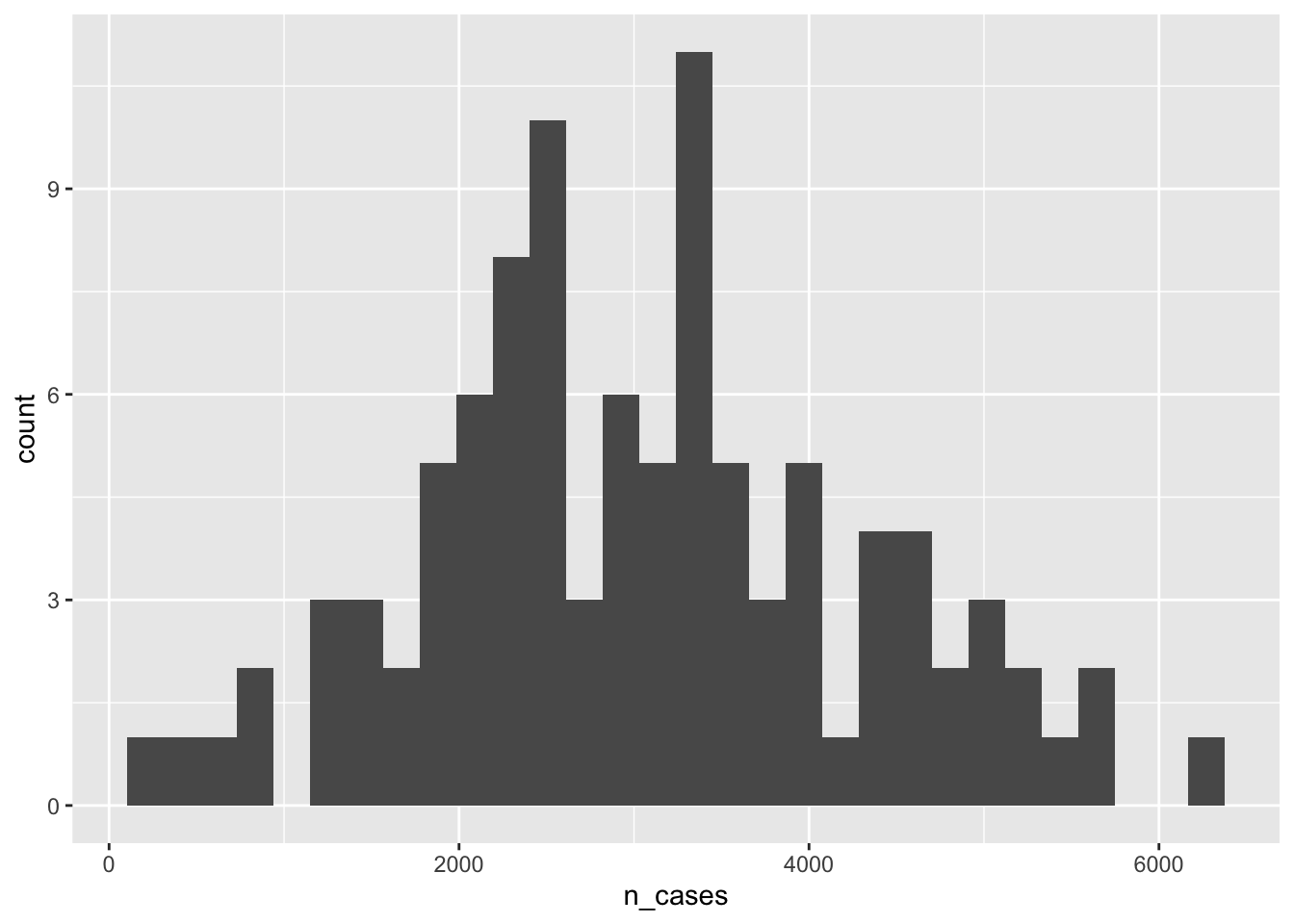
4.1.1 Define a function for replications
Now let’s randomly vary values of the variables over several replications. In this code, we will create a function that will create new variables whose values will randomly change. Functions are described in the functions chapter of R 4 Data Science. At the end of this module, I have another example of how to use a function in a dplyr pipe.
Create a function for the creation of this dataset, run it 500 times, and find the mean of the means over those 500 iterations. Our function’s one argument is rep_id_val. Its value is used in the mutate() step to create a variable called rep_id.
monte_carlo_sim_fun = function(rep_id_val){
monte_carlo_sim_df = 1:100 %>%
as_tibble() %>%
rename(county_id = value) %>%
mutate(
state = 1,
pop = rpois(n=n(), lambda=10000),
dem = rbinom(n=n(), size=1, prob =.5),
prev = rtruncnorm(
n=n(),
a=0,
b=1,
mean=0.05+(pop/50000)+(dem/10),
sd=0.05 +(pop/200000)+(dem/40)),
n_cases = as.integer(pop*prev),
rep_id = rep_id_val #add replication ID
)
}To see how the function works, run one iteration of it:
monte_carlo_sim_once = monte_carlo_sim_fun(rep_id_val = 5)
monte_carlo_sim_once## # A tibble: 100 × 7
## county_id state pop dem prev n_cases rep_id
## <int> <dbl> <int> <int> <dbl> <int> <dbl>
## 1 1 1 9858 1 0.177 1747 5
## 2 2 1 9890 0 0.424 4191 5
## 3 3 1 9960 0 0.137 1362 5
## 4 4 1 9885 0 0.425 4196 5
## 5 5 1 10003 1 0.517 5175 5
## 6 6 1 10000 1 0.350 3496 5
## 7 7 1 10134 0 0.248 2511 5
## 8 8 1 9834 0 0.189 1862 5
## 9 9 1 10050 1 0.157 1579 5
## 10 10 1 10221 1 0.133 1361 5
## # … with 90 more rows
## # ℹ Use `print(n = ...)` to see more rowsNow let’s run the function lots of times. Define the number of replications. Here, we create an integer vector ranging from 1 to 500.
rep_id_val_list = 1:500
class(rep_id_val_list)## [1] "integer"4.1.2 Run the replications
Simulate 500 versions of this state. In each replication, the values for the variables pop, dem, prev, and n_cases randomly vary according to their specified distribution. We use map_dfr() from the purrr package to run the simulation and then stack the results from each iteration on top of one another, akin to dplyr::bind_rows().
Take note of the unusual structure of this code. The function we created above, monte_carlo_sim_fun is inside of map_dfr(), and the list of replication ids, rep_id_val_list, is the object that begins the pipe sequence.
library(purrr) #make sure it's attached
set.seed(NULL) #allow it to vary differently each time.
monte_carlo_sim_lots = rep_id_val_list %>%
map_dfr(monte_carlo_sim_fun) Take a look at the output.
monte_carlo_sim_lots## # A tibble: 50,000 × 7
## county_id state pop dem prev n_cases rep_id
## <int> <dbl> <int> <int> <dbl> <int> <int>
## 1 1 1 9912 0 0.295 2926 1
## 2 2 1 10042 0 0.209 2098 1
## 3 3 1 9893 0 0.229 2265 1
## 4 4 1 9967 0 0.224 2229 1
## 5 5 1 10099 1 0.491 4954 1
## 6 6 1 10076 1 0.528 5322 1
## 7 7 1 9898 0 0.0668 661 1
## 8 8 1 10076 1 0.308 3106 1
## 9 9 1 10097 0 0.140 1416 1
## 10 10 1 9908 1 0.465 4605 1
## # … with 49,990 more rows
## # ℹ Use `print(n = ...)` to see more rowsHow many rows?
nrow(monte_carlo_sim_lots)## [1] 50000How many distinct values of rep_id?
n_distinct(monte_carlo_sim_lots$rep_id)## [1] 5004.1.3 Summarize results
What’s the distribution of n_cases_mean over Monte Carlo replications? This is not the variability of the number of cases within the state between counties but rather the variability of the mean number of county-level cases between replications.
monte_carlo_sim_lots %>%
group_by(rep_id,state) %>%
summarise(
n_cases_mean = mean(n_cases),
n_cases_sd = sd(n_cases)) %>%
ggplot(aes(n_cases_mean))+
geom_histogram()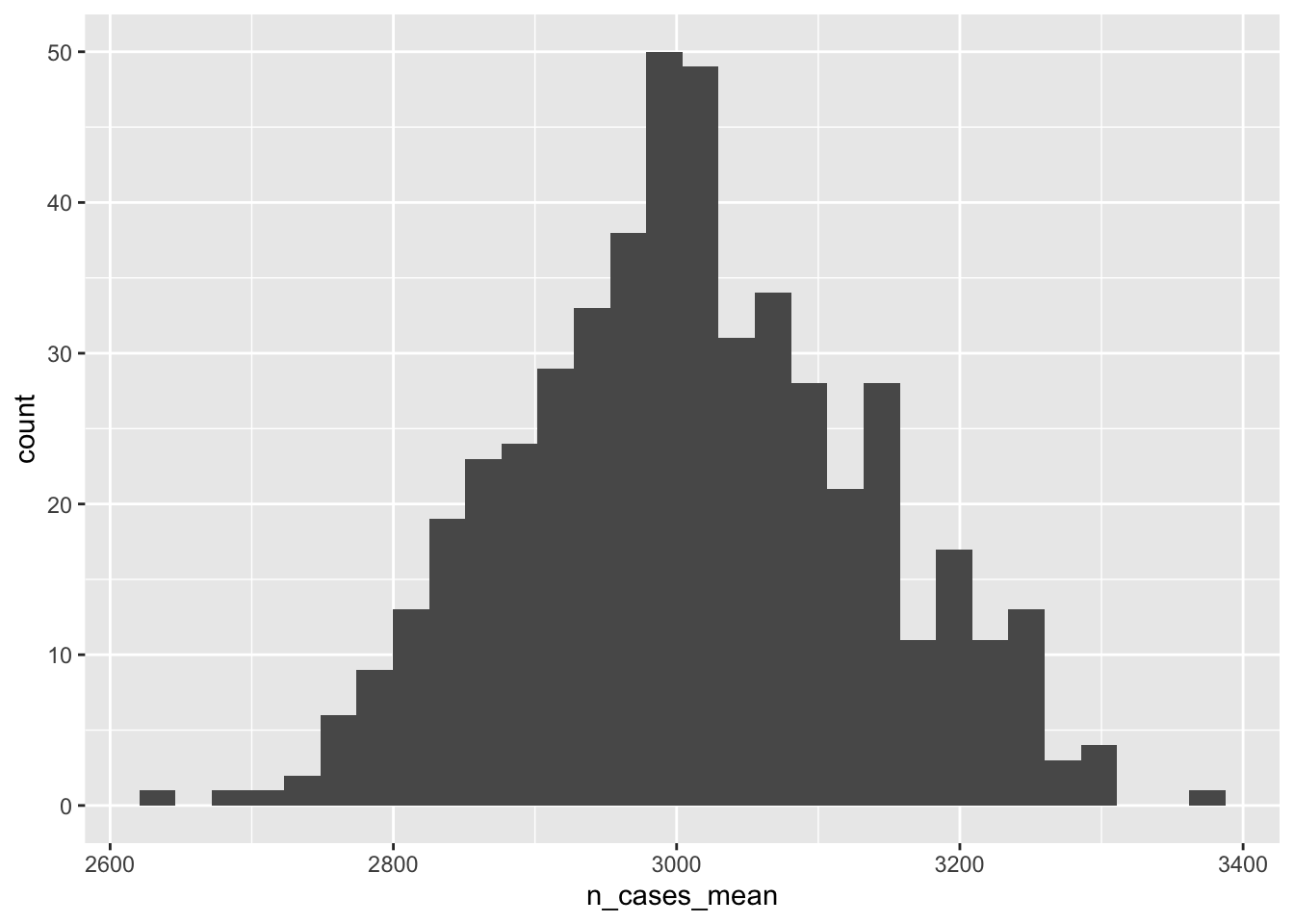
What is the 2.5th, 50th (median), and 97.5th percentile of the mean number of cases between replications? This could be used to report a confidence interval around that estimated mean.
monte_carlo_sim_lots_summary = monte_carlo_sim_lots %>%
group_by(rep_id,state) %>% #group by both rep id and state
summarise(
n_cases_mean = mean(n_cases),
n_cases_sd = sd(n_cases)) %>%
group_by(state) %>% #now collapse over rep id
summarise(
n_cases_mean_ll = quantile(n_cases_mean, probs = 0.025, na.rm=TRUE),
n_cases_mean_med = quantile(n_cases_mean, probs = 0.5, na.rm=TRUE),
n_cases_mean_ul = quantile(n_cases_mean, probs = 0.975, na.rm=TRUE)
) %>%
ungroup() %>%
mutate(simulation_type = "monte-carlo")
monte_carlo_sim_lots_summary## # A tibble: 1 × 5
## state n_cases_mean_ll n_cases_mean_med n_cases_mean_ul simulation_type
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 1 2779. 3006. 3243. monte-carlo4.2 Bootstrap
Now let’s bootstrap monte_carlo_sim_frozen, again supposing that even though it was generated randomly, it is now viewed as a single frozen sample - the one we drew and have access to. We can estimate the sampling distribution by re-sampling it with replacement with sampling probability of 1, meaning all rows will be re-sampled. Because we are sampling with replacement, in a given sample, some counties will repeat, and some will not appear at all.
Here’s one sample:
monte_carlo_sim_one_boot = monte_carlo_sim_frozen %>%
slice_sample(prop=1,replace=TRUE)Take a look:
monte_carlo_sim_one_boot## # A tibble: 100 × 6
## county_id state pop dem prev n_cases
## <int> <dbl> <int> <int> <dbl> <int>
## 1 91 1 9947 1 0.377 3752
## 2 5 1 10132 0 0.243 2464
## 3 94 1 10091 1 0.269 2716
## 4 49 1 10033 1 0.347 3486
## 5 45 1 10006 1 0.396 3961
## 6 45 1 10006 1 0.396 3961
## 7 56 1 10007 0 0.0461 460
## 8 28 1 10154 1 0.446 4533
## 9 11 1 9885 1 0.329 3251
## 10 41 1 10015 1 0.468 4684
## # … with 90 more rows
## # ℹ Use `print(n = ...)` to see more rowsAs expected, we have the same number of rows, but fewer unique values for county_id. Some are repeating.
nrow(monte_carlo_sim_one_boot)## [1] 100n_distinct(monte_carlo_sim_one_boot$county_id)## [1] 63Repeat this bootstrap procedure 500 times by first writing a function and then iterating replications through that function using purrr::map_dfr()
4.2.1 Define a function for replications
boot_fun = function(rep_id_val){
monte_carlo_sim_boot = monte_carlo_sim_frozen %>%
slice_sample(prop=1,replace=TRUE) %>%
mutate(rep_id = rep_id_val) #to keep track of reps
}4.2.2 Run the replications
Simulate 500 versions of this re-sampling. We again use map_dfr() from the purrr package to run the function and then stack the results on top of one another. Again take note of the unusual structure of this code. The function, boot_fun, is inside of map_dfr(), and the vector of replication ids, rep_id_val_list, begins the pipe sequence.
boot_lots = rep_id_val_list %>%
map_dfr(boot_fun) 4.2.3 Summarize results
boot_lots## # A tibble: 50,000 × 7
## county_id state pop dem prev n_cases rep_id
## <int> <dbl> <int> <int> <dbl> <int> <int>
## 1 77 1 10070 0 0.395 3975 1
## 2 61 1 9910 1 0.520 5148 1
## 3 84 1 10247 0 0.291 2983 1
## 4 51 1 10006 1 0.420 4205 1
## 5 15 1 9842 0 0.197 1943 1
## 6 90 1 9986 1 0.138 1375 1
## 7 77 1 10070 0 0.395 3975 1
## 8 34 1 9924 1 0.440 4363 1
## 9 90 1 9986 1 0.138 1375 1
## 10 38 1 10078 0 0.394 3974 1
## # … with 49,990 more rows
## # ℹ Use `print(n = ...)` to see more rowsWhat’s the distribution of n_cases_mean over bootstrap replications?
boot_lots %>%
group_by(rep_id,state) %>%
summarise(
n_cases_mean = mean(n_cases),
n_cases_sd = sd(n_cases)) %>%
ggplot(aes( n_cases_mean))+
geom_histogram()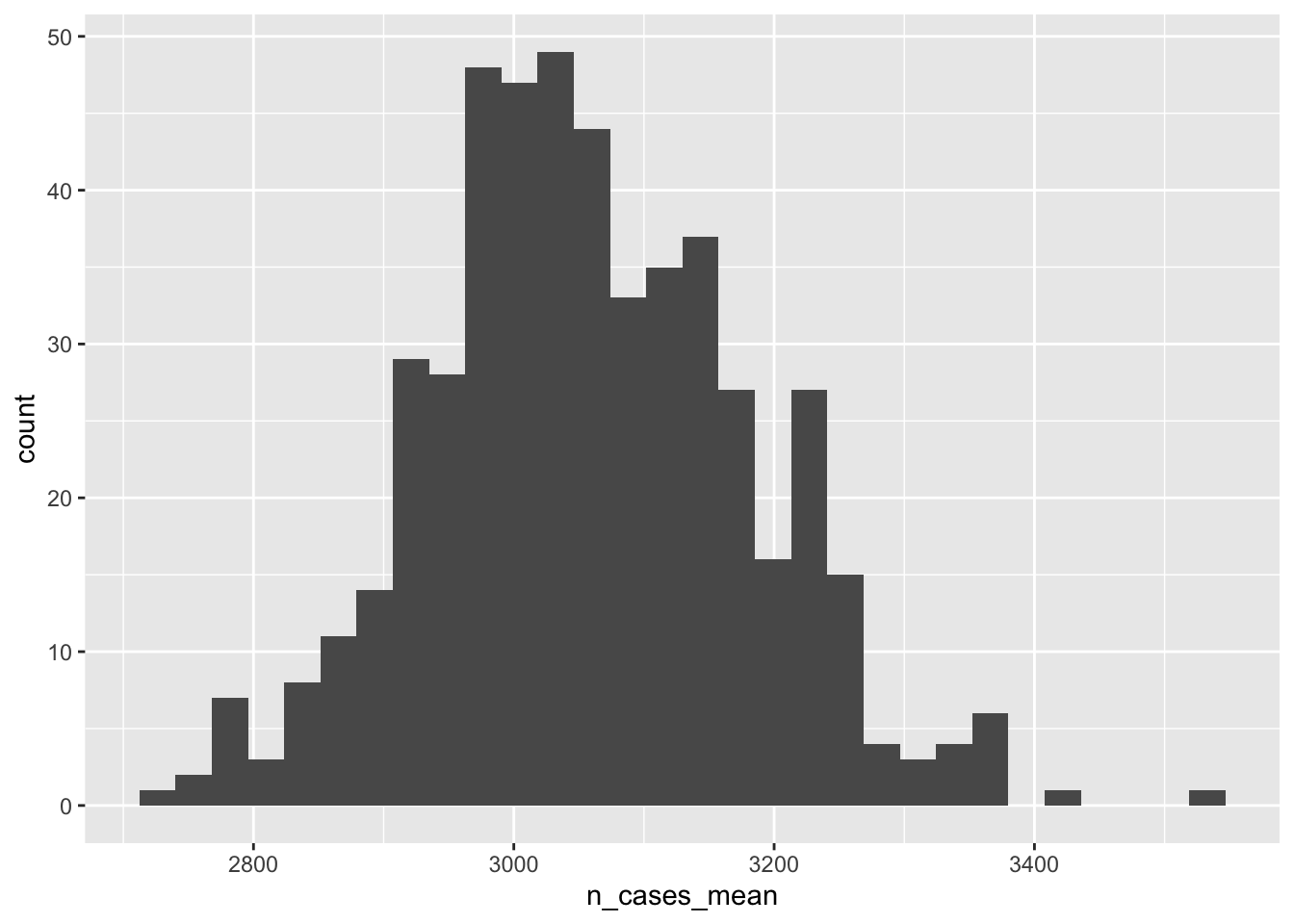
We can use the empirical distribution of re-sampled results to estimate a confidence interval for the sampling distribution. This is a confidence interval for the estimated mean number of cases in the state:
boot_lots_summary = boot_lots %>%
group_by(rep_id,state) %>% #group by both rep id and state
summarise(
n_cases_mean = mean(n_cases),
n_cases_sd = sd(n_cases)) %>%
group_by(state) %>% #now collapse over rep id
summarise(
n_cases_mean_ll = quantile(n_cases_mean, probs = 0.025, na.rm=TRUE),
n_cases_mean_med = quantile(n_cases_mean, probs = 0.5, na.rm=TRUE),
n_cases_mean_ul = quantile(n_cases_mean, probs = 0.975, na.rm=TRUE)
) %>%
ungroup() %>%
mutate(simulation_type = "bootstrap")
boot_lots_summary## # A tibble: 1 × 5
## state n_cases_mean_ll n_cases_mean_med n_cases_mean_ul simulation_type
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 1 2821. 3050. 3318. bootstrapHow does this estimate of the sampling distribution of n_cases_mean align with the truth? We happen to know the truth here. It’s the distribution of n_cases_mean between the Monte Carlo simulations, defined above.
monte_carlo_sim_lots_summary %>%
bind_rows(boot_lots_summary)## # A tibble: 2 × 5
## state n_cases_mean_ll n_cases_mean_med n_cases_mean_ul simulation_type
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 1 2779. 3006. 3243. monte-carlo
## 2 1 2821. 3050. 3318. bootstrap5 Summary of Monte Carlo simulations and bootstrapping
Advantages of these computation-based simulation methods:
They make explicit where the variation is coming from, aiding in intuition.
They easily accommodate correlation between variables, avoiding difficult math.
Comparison between the two:
Difference: Is variability specified by the user or is it estimated from the sample?
In common: Both use repeated sampling to estimate uncertainty. Monte Carlo simulations may sample from a specified distribution to generate values for a variable, and bootstrapping samples the rows of the data at hand.
Broad steps for each:
- Define a function that contains steps of the analysis with variability.
- Run that function lots of times using
purrr::map_dfr(). - Summarize the distribution of the results. Conventionally, to report percentile-based confidence intervals,9 take the 2.5th, and 97.5th percentiles.
6 More on functions
In addition to their use for simulations as above, functions can also be used simply to reduce repetition in code. Sometimes you end up writing the same or similar code many times and apply that code to several datasets. For example, above, we wrote an almost identical sequence of dplyr functions to define both monte_carlo_sim_frozen and the function, monte_carlo_sim_fun().
Here is an example sequence of dplyr steps combined into one function.
do_some_dplyr_stuff = function(df){
df %>%
mutate(
example_var_x=rnorm(n=n(), mean=0, sd=1),
example_var_y=4,
example_var_z = rbinom(n=n(), size=1, prob=.2)
) %>%
dplyr::select(state, county_id, starts_with("example"))
} The argument of the function here is a dataframe or tibble arbitrary called df . When we run this function in a piped chain, that df will be taken as the implied object, and the function can be run as if it were any other dplyr function.
Let’s apply that function to one county from our monte_carlo_sim_frozen dataset.
function_result_one_county = monte_carlo_sim_frozen %>%
filter(county_id==2) %>%
do_some_dplyr_stuff()
function_result_one_county## # A tibble: 1 × 5
## state county_id example_var_x example_var_y example_var_z
## <dbl> <int> <dbl> <dbl> <int>
## 1 1 2 0.251 4 0References
Copyright © 2022 Michael D. Garber